|
I am a final-year Ph.D. student at Xi'an Jiaotong University (XJTU), my advisors are Xueming Qian. Also, I was a visiting student at Vision and Learning Lab, University of California, Merced, supervised by Ming-Hsuan Yang. I was fortunate to be involved in internship program at Megvii Research, Microsoft Research Asia (MSRA). I received the B.S. degree from School of the Information engineering, XJTU in 2019. I'll be an assistant professor at XJTU in the fall of 2025. Email / CV / Google Scholar / LinkedIn / Github |

|
|
|
|
I'm interested in image/video restoration, low-quality/degraded detection, and fine-grained recognition. Much of my research is about low-level vision. Representative papers are highlighted. (* indicates equal contribution) |
|
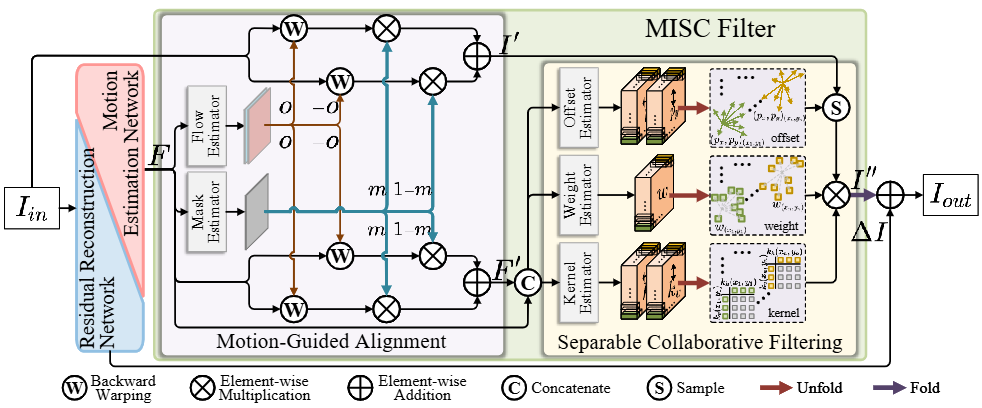
Chengxu Liu, Xuan Wang, Xiangyu Xu, Ruhao Tian, Shuai Li, Xueming Qian, Ming-Hsuan Yang CVPR, 2024 [ArXiv] [Code] [Supp] We introduce a new perspective to handle motion blur in image space instead of features and propose a novel motion-adaptive separable collaborative (MISC) filter. |
|
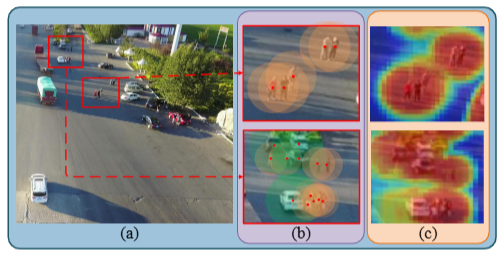
Nengzhong Yin*, Chengxu Liu*, Ruhao Tian, Xueming Qian IEEE TMM, 2024 [PDF] [Code] We propose a novel one-step detector, called SDPDet , to enable effective object learning in drone-view images. |
|
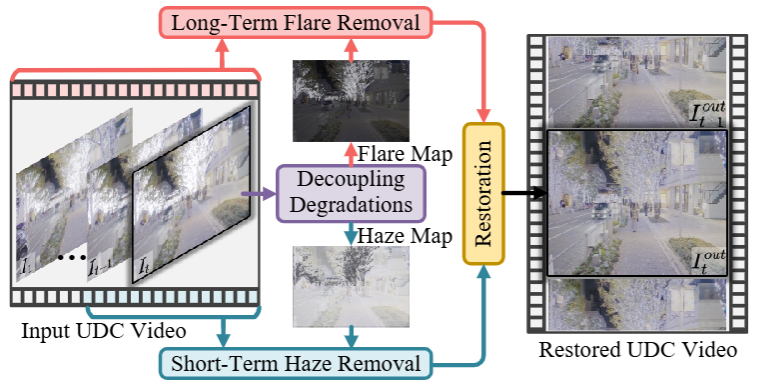
Chengxu Liu, Xuan Wang, Yuanting Fan, Shuai Li, Xueming Qian AAAI, 2024 [PDF] [ArXiv] [Code] We propose a novel network with long- and short-term video representation learning by decoupling video degradations for the UDC video restoration task (DDRNet), which is the first work to address UDC video degradation. |
|
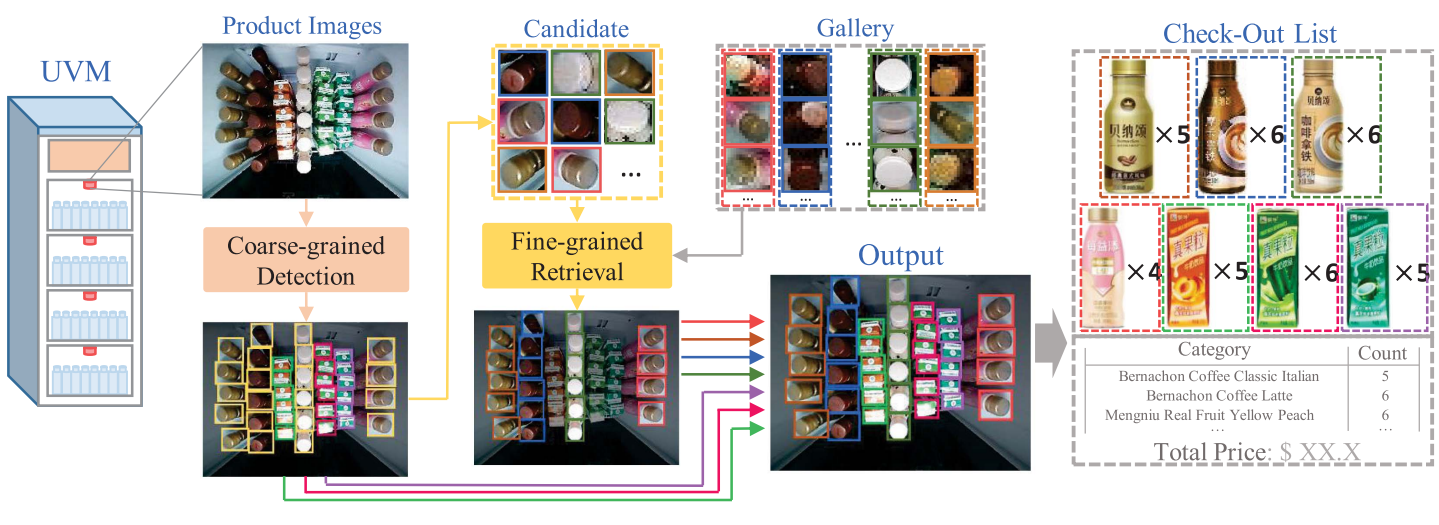
Chengxu Liu, Zongyang Da, Yuanzhi Liang, Yao Xue, Guoshuai Zhao, Xueming Qian IEEE TII, 2023 We propose a product recognition approach based on intelligent UVMs, called Split-Check, which first splits the region of interest of products by detection and then check product by instance-level retrieval. |
|
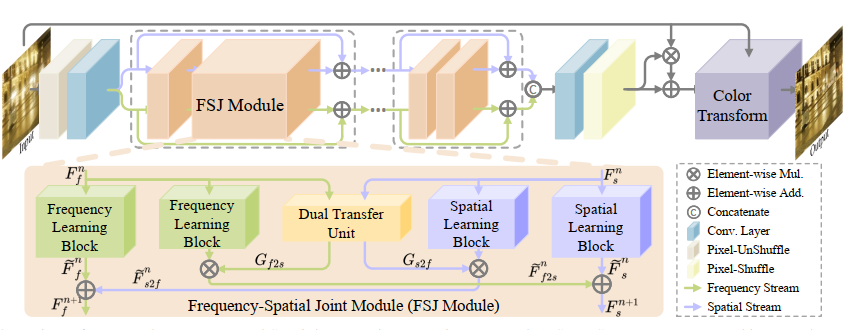
Chengxu Liu, Xuan Wang, Shuai Li, Yuzhi Wang, Xueming Qian ICCV, 2023 [PDF] [ArXiv] [Code] [Supp] We introduce a new perspective to handle various diffraction in UDC images by jointly exploring the feature restoration in the frequency and spatial domains, and present a Frequency and Spatial Interactive Learning Network (FSI). |
|
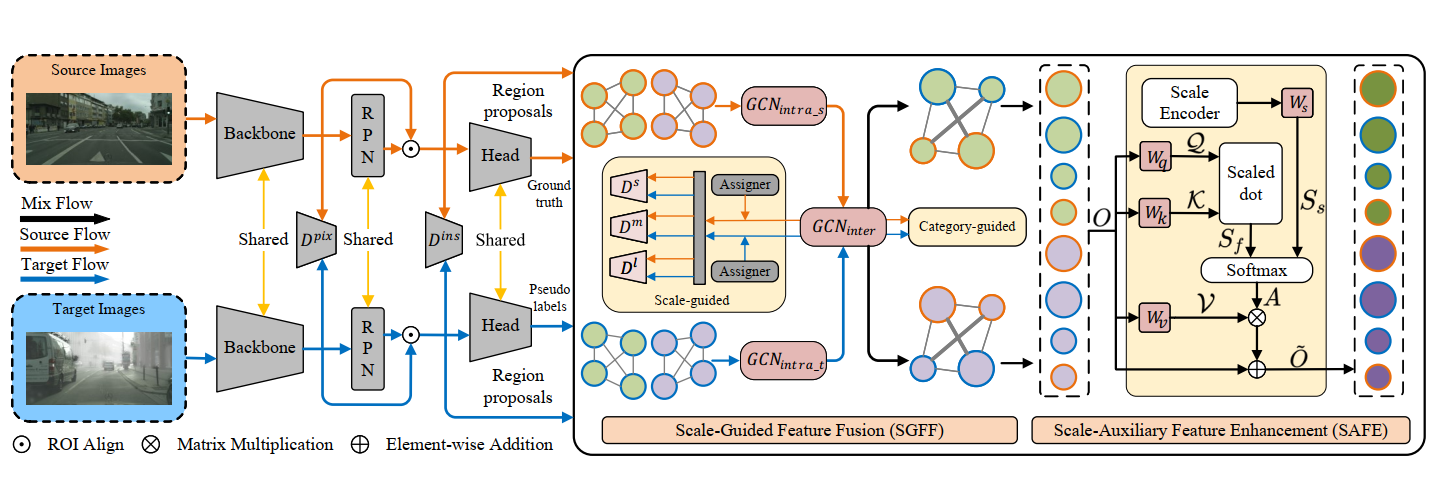
Changlong Gao*, Chengxu Liu*, Yujie Dun, Xueming Qian ICCV, 2023 [PDF] [Code] For better category-level feature alignment, we propose a novel DAOD framework of joint category and scale information, dubbed CSDA, such a design enables effective object learning for different scales. |
|
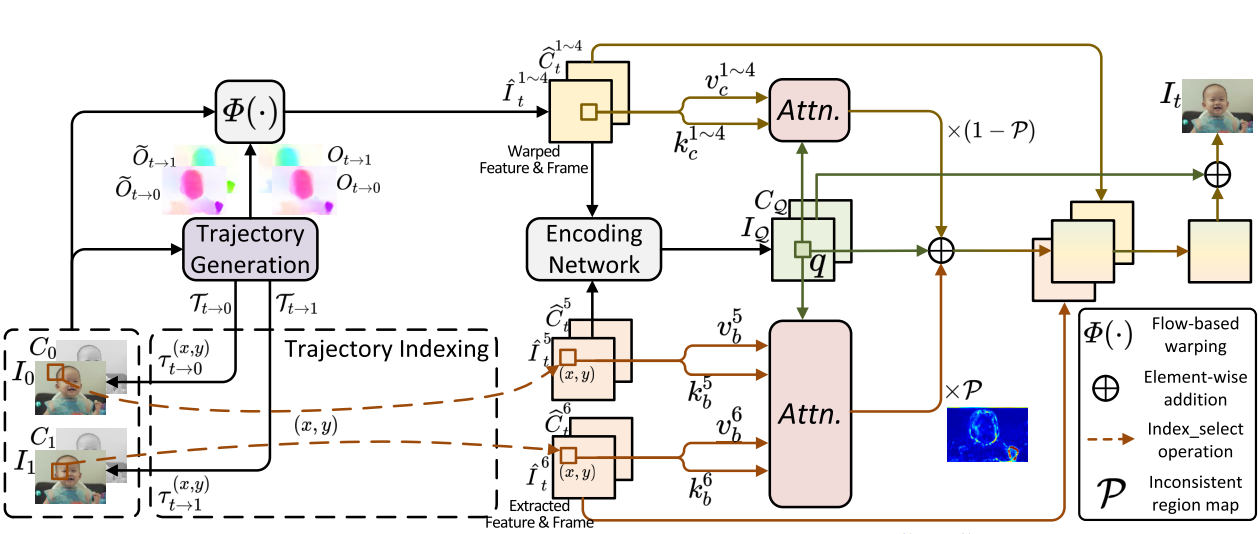
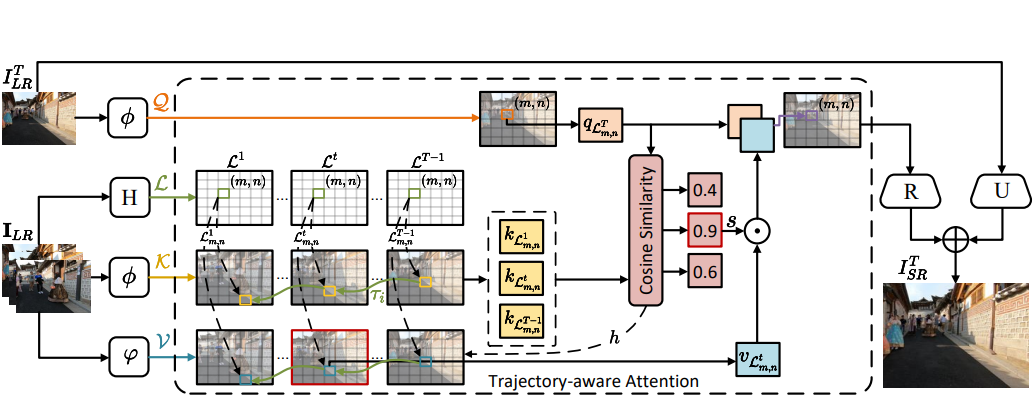
Chengxu Liu, Huan Yang, Jianlong Fu, Xueming Qian IEEE TIP, 2023 [PDF] [arXiv] [Code] We propose a novel Trajectory-aware Transformer for Video Frame Interpolation (TTVFI), which formulate the warped features with inconsistent motions as query tokens, and formulate relevant regions in a motion trajectory from two original consecutive frames into keys and values. |
|
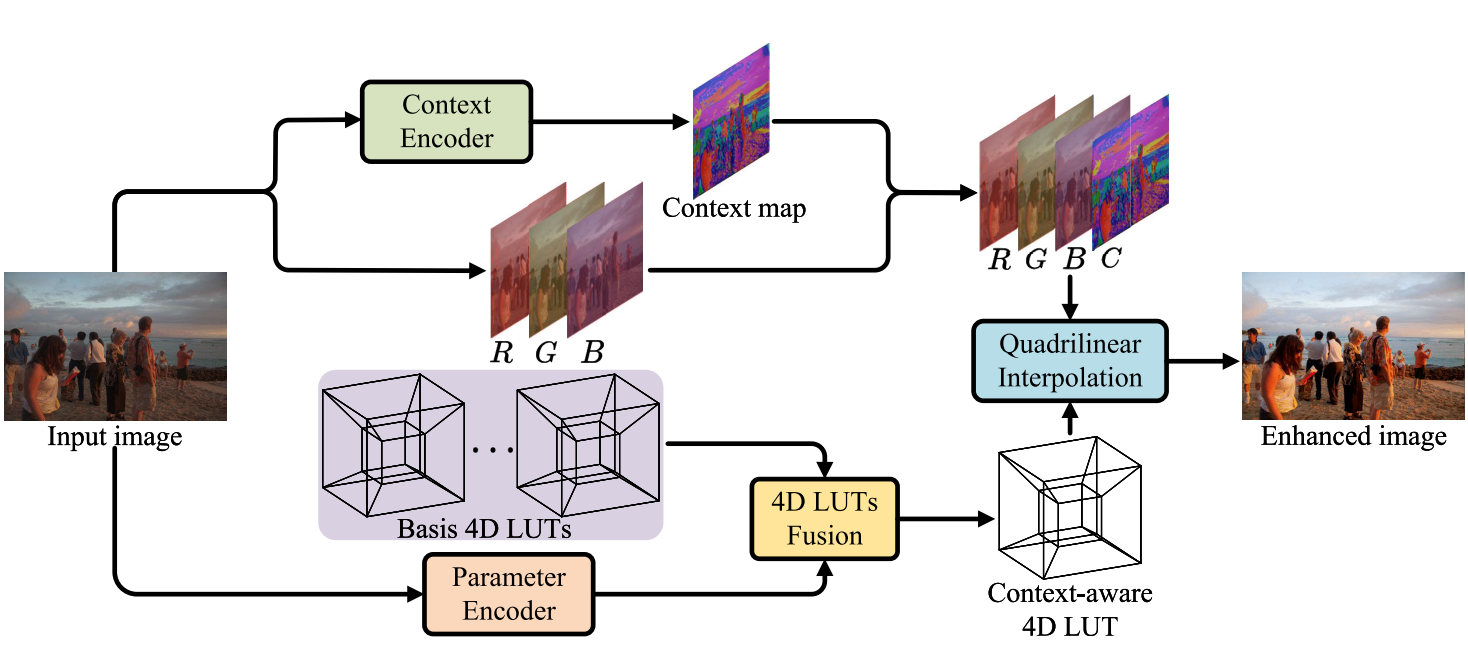
Chengxu Liu, Huan Yang, Jianlong Fu, Xueming Qian IEEE TIP, 2023 [PDF] [arXiv] [Code] We propose a novel learnable context-aware 4-dimensional lookup table (4D LUT), which achieves content-dependent enhancement of different contents in each image via adaptively learning of photo context. |
|
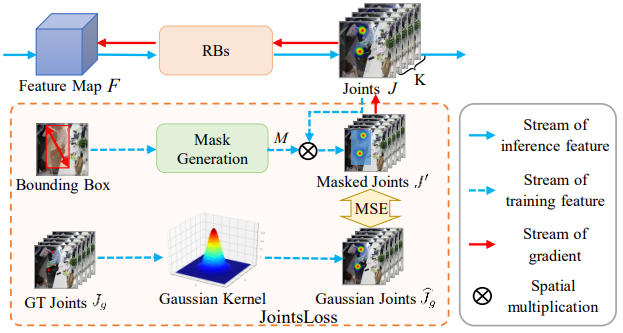
Chengxu Liu, Yaru Zhang, Yao Xue, Xueming Qian IEEE TCSVT, 2023 [PDF] We focus on human joints and take one step further to enable effective behavior characteristics learning in office scenarios. In particular, we propose a novel Adaptive Joints Enhancement Network (AJENet). |
|
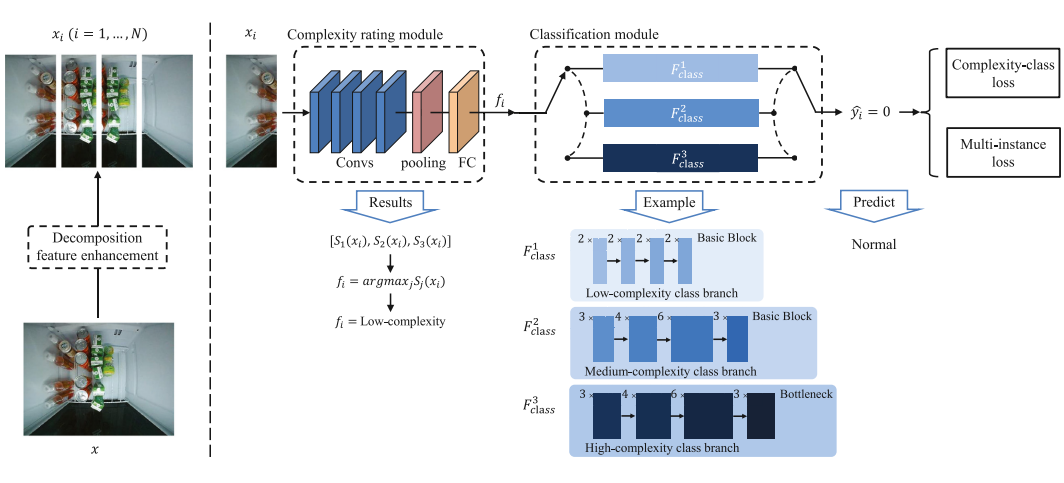
Zongyang Da, Yujie Dun, Chengxu Liu, Yuanzhi Liang, Yao Xue, Xueming Qian KBS, 2023 We propose an unmanned retail anomaly detection method based on deep convolutional neural networks (CNNs) called the complexity-classification anomaly detection (ClassAD) framework. |
|
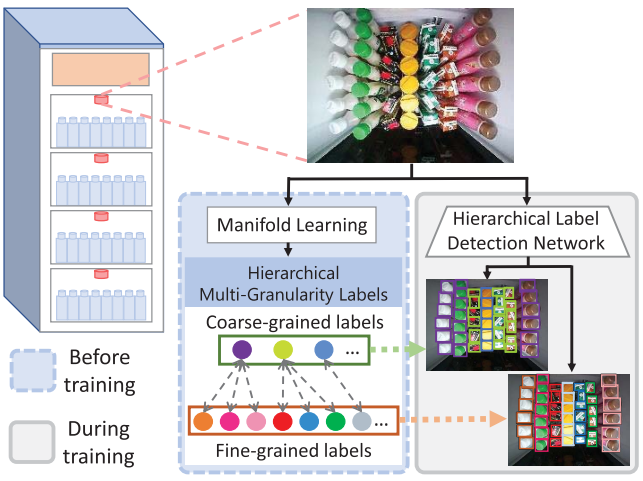
Chengxu Liu, Zongyang Da, Yuanzhi Liang, Yao Xue, Guoshuai Zhao, Xueming Qian IEEE TNNLS, 2022 We propose a method for large-scale categories product recognition based on intelligent UVMs. The highlights of our method are mine potential similarity between large-scale category products and optimization through hierarchical multigranularity labels |
|
Chengxu Liu, Huan Yang, Jianlong Fu, Xueming Qian CVPR (Oral presentation), 2022 [PDF] [arXiv] [Code] [Supp] We propose a novel Trajectory-aware Transformer for Video Super-Resolution (TTVSR), which formulate video frames into several pre-aligned trajectories which consist of continuous visual tokens. For a query token, self-attention is only learned on relevant visual tokens along spatio-temporal trajectories. |
|
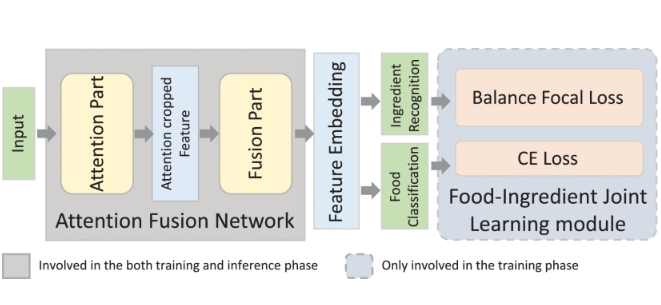
Chengxu Liu, Yuanzhi Liang, Yao Xue, Xueming Qian, Jianlong Fu IEEE TCSVT, 2021 We propose an Attention Fusion Network (AFN) and Food-Ingredient Joint Learning module for fine-grained food and ingredients recognition. |
|
|
|
|
|
Based on Jon Barron's website.
|